Elasticsearch Python Client를 활용한 ‘검색’ 입문
‘검색’ 엔진 엘라스틱 서치
현존하는 다양한 어플리케이션들을 살펴보면 기능적 요구사항을 넘어 서비스 사용성과 품질을 보장하기 위해 ‘검색’ 기술에 의존하고 있다. 하지만, 검색은 다양한 기술들의 융-복합체이므로 쉽게 접근하기 어렵고 누구나 펼치기 어려운 배경 지식을 필요로 한다. 이런 검색 기술의 접근성을 높이고 구현의 용이성을 제공하는 솔루션들로는 아파치 루씬(Apache Lucene) 라이브러리에서 파생된 아파치 솔라(Apache Solr), 엘라스틱서치(Elasticsearch)등이 있다.

엘라스틱 서치는 분산구조를 표방한 RESTful 검색 엔진이다. NoSQL의 특징인 정형, 비정형, 위치정보 등 원하는 방법으로 다양한 유형의 데이터를 지원하고, 검색 할 수 있다. 엘라스틱의 장점은 간편한 시작과 빠르게 관련 지식을 습득하기 좋은 구조로 되어 있다.
시스템 측면에서는 작은 규모로 시작되어도 수평적으로 확장할 수 있도록 설계되어 있어 더 많은 용량이 필요할 때마다 노드를 추가하는 것만으로도 클러스터 관리에 많은 리소스를 들이지 않고, 분산처리에 능하다. 분산처리에 강점이 있기 때문에 문제가 있는 노드는 클러스터 내부의 다른 복제본을 통해 데이터의 안정성과 서비스 지속성을 보장해준다.
기능적으로는 클러스터 내부에 다수의 인덱스를 생성, 저장, 관리 할 수 있기 때문에 쿼리와 인덱스간의 다대다 관계를 지원한다. 별도의 스키마 개념이 없이도 데이터 인덱싱과 검색을 지원하며, 추가로 간편한 인터페이스를 위해 CRUD에 대응되는 RESTful API를 제공한다.
필자는 버즈니에서 파이썬과 함께 엘라스틱서치를 기반으로 검색 엔진을 구축 하고, 모바일 홈쇼핑 포털 앱 ‘홈쇼핑모아’의 검색 서비스로 제공하고 있다. 엘라스틱서치의 필수 구성 요소들을 통해 검색 엔진에 대한 이해도를 높이고 서비스로서의 활용 가능성과 효용 가치를 공유하고자 한다.
엘라스틱서치 사용
컴퓨터 공학도 또는 개발자라면 알만한 뻔하고 뻔한 주제를 통해 엘라스틱서치를 쉽고 빠르게 경험하려 한다. 그것은 바로 오랜 시간 동안 관계형 데이터베이스에서 단골로 사용됐던 검색이 가능한 주소록 만들기다. 설치-색인-수정/삭제-검색의 순서로 진행되며 실제 아무도 상관없는 임의로 생성 주소록을 JSON파일로 저장해 본 예제에 사용했다. 예제에서는 파이썬과 엘라스틱서치 버전 6.3.2와 엘라스틱서치 파이썬 클라이언트를 사용했으며 일련의 과정을 그대로 따라 할 수 있도록 코드와 글을 함께 담았다.
1. 설치
엘라스틱서치는 다양한 형태의 설치 방법을 제공하고 있다. zip/tar.gz, deb, rpm, msi, docker 의 거의 대부분의 설치 형태를 지원하고 있다. 이 중 필자는 docker를 사용한 설치를 사용하고 있고, 여러분에게 추천한다. 엘라스틱서치의 설치는 기본적으로 쉽고 간편한 축에 속하지만, Docker를 사용하면 더욱 편리하기 때문이다.
설치 방법은 간단하다. 엘라스틱에서 제공하는 Docker Image(https://www.docker.elastic.co)를 내려받고, 실행만 하면 아래 그림과 같이 엘라스틱서치의 기본적인 설치가 끝난다. 그리고 곧바로 이어서 컨테이너를 실행하면 된다.
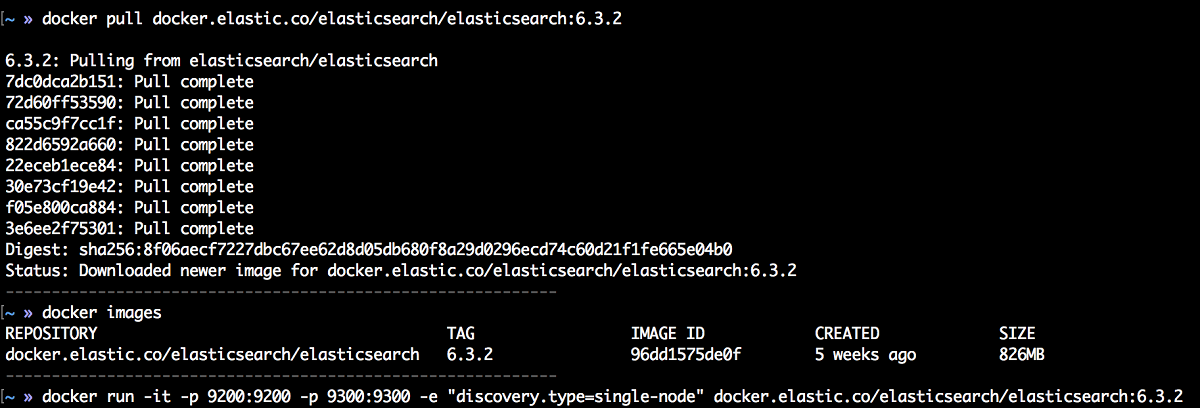
추가로, 파이썬 클라이언트를 사용해보기로 했으니 클라이언트 패키지를 설치하도록 한다. 사용된 엘라스틱서치 버전은 6.3.2 이지만, 파이썬 클라이언트 버전은 아직 6.3.1까지 제공되고 있고, 사용에 전혀 문제가 되지 않는 관계로 그대로 사용했다.

2. 클라이언트 연결 정의
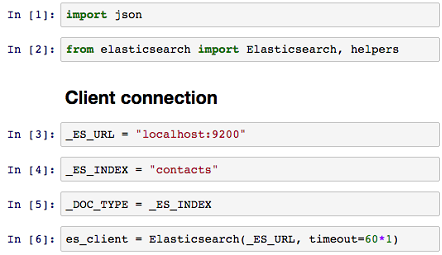
로컬 또는 외부에서 엘라스틱서치를 사용하기 위해 URL 정보와 사용할 Index, type 정보를 사용하여 클라이언트를 정의해준다. 본 예제는 로컬에 실행되어있는 엘라스틱서치의 9200번 포트를 사용해 ‘contacts’ 색인명과 타입명을 사용한다.
3. 색인 생성 & 맵핑
엘라스틱은 기본적으로 필드 데이터타입으로 text, keyword, date, long, double, boolean, ip를 제공한다. 또한 object나 nested을 통한 계층구조, geo_point, geo_shape, completion 등의 특수한 타입을 지원하고 있다.
2개의 샤드와 샤드당 1개의 레플리카로 샤드를 구성했고, [“name”, “age”, “gender”, “company”, “email”, “phone”, “address”] 의 필드로 필드 타입 맵핑을 정의한다.


생성에 사용되는 API는 indices.create 다. 먼저 정의한 색인명과 색인정보를 통해 색인을 생성해 준다.
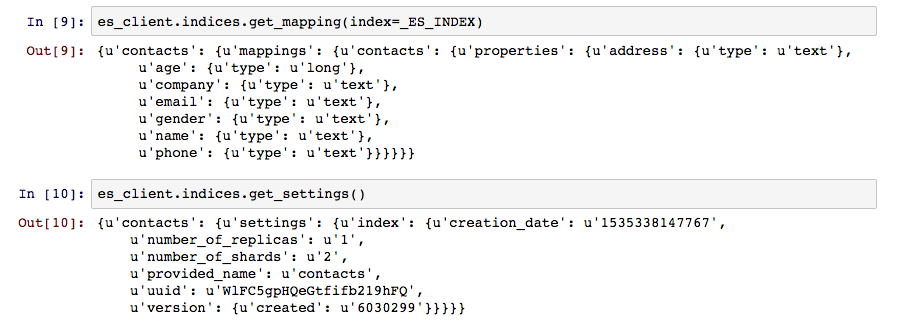
indices.get_mapping을 통해 contacts라는 이름의 색인과 타입을 확인 할 수 있고, 7개의 필드가 포함된 색인의 맵핑 정보를 확인 할 수 있다. 또한 indices.get_settings는 요청한 샤드와 레프리카 수를 포함한 색인의 설정 정보를 제공해준다.
4. 문서 색인화
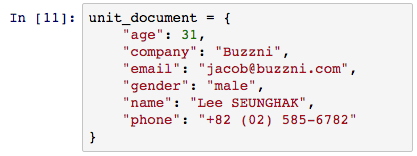
contacts 색인에 단일 문서를 추가 해보기 위해 필자의 사소한 개인정보를 활용해보도록 하겠다. 색인 생성에서 미리 정의된 필드 정보에 따라 데이터를 준비한다.
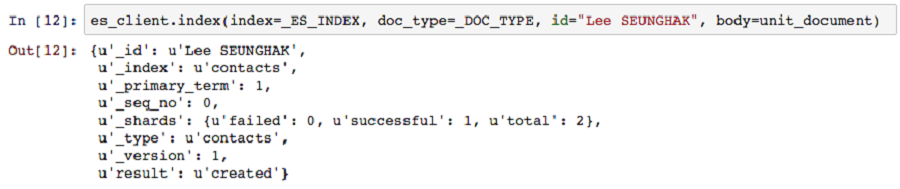
문서 색인화는 엘라스틱서치에 색인명과 타입을 명시해줘야 한다. 예제에서 “Lee SEUNGHAK”의 ID 값을 명시 해주고 있지만, 사용 목적에 따라 입력하지 않으면 자동생성 된다. 요청 정보에 색인 위치와 관련 정보를 싣고 바로 클라이언트에 index 요청을 한다. 응답의 내용에 문서 색인의 성공 여부와 간단한 상태 정보를 얻을 수 있다. 혹여, 명시적인 ID 값을 부여하지 않았더라도 문제가 되지 않는다. 미입력시 자동으로 ID가 생성되기 때문에 응답 정보에서 확인 할 수 있다.
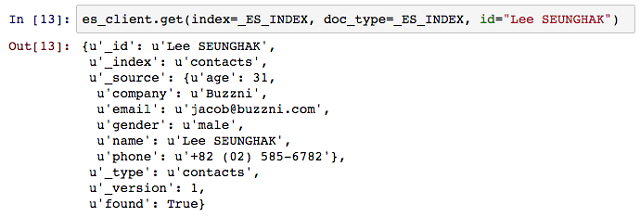
색인된 문서의 내용은 ID와 색인 위치 정보를 통해 손쉽게 조회할 수 있고, 응답된 _source 필드를 통해 해당 문서의 필드와 필드 값을 상세히 확인 할 수 있다.
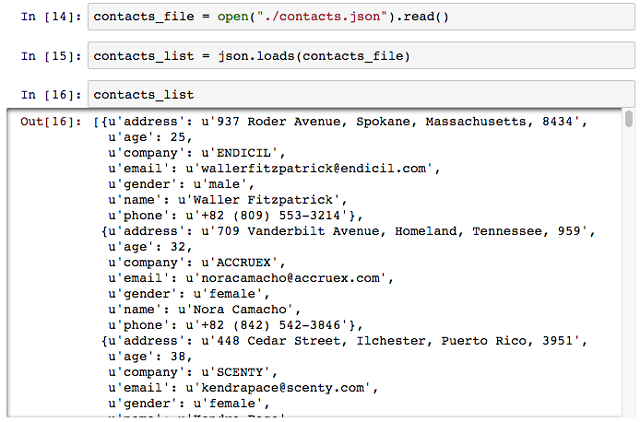
단일 문서 색인을 통해서 많은 양의 문서를 효율적으로 처리 하기에는 다소 무리가 있다. 이에 Bulk를 통해 많은 양의 문서를 색인하는 방법을 알아보도록 하자. 많은 양의 문서를 색인해보기 위해서는 많은 문서가 필요한 것은 당연지사, 필자는 JSON형태로 문서를 임의 생성하여 준비했다.
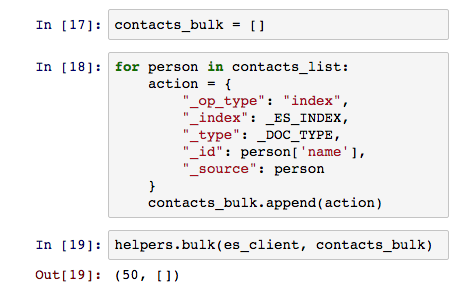
Bulk는 클라이언트 API에서 두 가지 형태로 제공 된다. index나 get 같이 직접 API를 호출 방식과 helpers를 이용한 방식이다. 동일하게 bulk의 기능을 충실히 수행하지만, 한 가지 큰 차이가 있다. 바로 세그먼트화. helpers.bulk는 원하는 수만큼 나누어 여러 번에 걸쳐 전송을 도와준다. 서버나 네트워크의 상황에 따라 안정적인 전송 보장하기 위한 훌륭한 도구로 사용된다.
bulk는 다양한 문서가 혼합되어 사용될 수 있기 때문에 개별적으로 색인 정보를 포함시켜야 한다. 또한 색인을 포함한 create, update, delete를 동시에 지원하기 때문에 사용에서 다양한 상황에서 매우 유용하게 사용된다.

5. 문서 관리
색인 외에 문서를 다루는 방법은 다양하다. 그중에 exists, update, delete만 골라서 간단히 살펴보도록 하겠다.
exists는 말 그대로 존재의 여부를 확인해주는 예의 바른 API다. 그 정도가 너무 심해서 True / False로만 응답을 준다. 빠르고 가볍게 사용할 수 있기 때문에 본격적으로 문서에 접근하기 전에 존재 여부에 따라 혹여 생길 수 있는 Exception을 예방하는데 큰 역할을 한다.
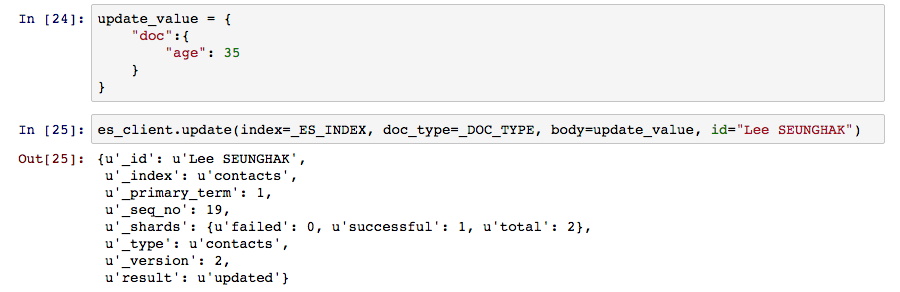
update는 문서의 잘못된 값이나 누락된 값을 조정해주고 채워주는 역할을 한다. update를 사용할 때는 작은 단위의 수정을 할 때 사용 하는 것이 좋다. overwrite처럼 동작할 것으로 생각되지만 실제로 update는 엔진 내부에서 delete-index의 순서로 동작하기 때문에 많은 변경이 이루어지는 내용이라면 명시적으로 색인을 다시 하는 것이 사용성 측면에서 나은 이해도를 준다.
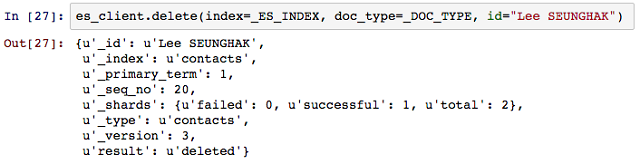
delete는 더이상 사용하지 않는 문서를 삭제하여 정리하는 역할을 한다. 소수의 문서를 삭제 하는 것은 엔진에 무리나 부담을 주지 않지만, 색인 자체의 문제로 문서를 정리해야 한다면 색인 자체를 다시 생성 하는 것이 더 효율적이다.

추가로, update와 delete는 id를 지정해 하나씩 정리 대상을 지정하기 때문에 다수의 동작이 필요로 할 때는 앞서 언급한 bulk를 이용하는 것이 효과적이다.
6. 문서 검색
엘라스틱서치는 검색을 위한 검색을 위해서 Query DSL이라는 전용 언어를 제공한다. 매우 다채롭게 쓰일 수 있기 때문에 무작정 처음부터 끝까지 알기에는 쉽지 않다. 하지만, 특수한 경우를 제외하고는 실제로 쓰이는 내용은 반복되기 때문에 겁먹지 않아도 된다.
Query DSL의 기본적인 뼈대의 구성은 query, from, size, sort로 이루어진다. query는 검색을 위한 필터나 조건 등을 정의하는 영역으로 내부에 다양한 조건 연산자와 임의로 작성이 가능한 스크립트 등이 포함된다. from과 size는 필요한 검색 결과의 위치와 순서, 개수를 선택이 가능하며, sort는 검색 결과에 추가로 필요한 정렬을 정의해 사용할 수 있도록 도와준다.
주소록을 위한 검색엔진이 구성됐으니 직접 검색을 해보자. 필자의 소소한 개인정보는 위의 delete를 통해서 사라졌으니 다른 가상의 인물을 찾아보자. match query만을 사용해 gibson이라는 글자가 이름에 포함된 사람을 찾아 보겠다. name 필드에 gibson을 매칭해 첫 번째 검색결과부터 20개까지 낮은 나이순으로 정렬되도록 Query DSL을 구성한다.
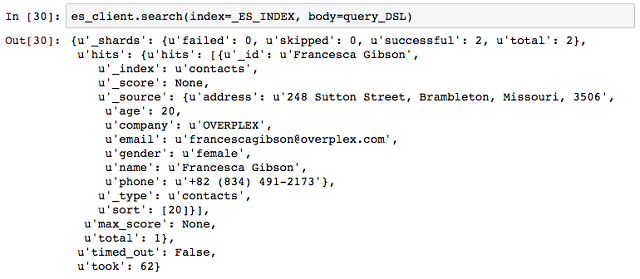
검색 결과 Paul Gibson과 Francesca Gibson 2개의 문서로 응답됐다. 둘 다 name 필드에 gibson이 포함돼 있으며, 나이순 정렬에 따라 31세인 Paul Gibson이 높은 순위에 위치하도록 나왔다.
짧은 시간 안에 설치부터 간단한 검색까지 할 수 있게 됐다. 이 주소록의 검색엔진은 기능과 성능은 여러분의 몫이다. 엘라스틱서치의 다양한 인터페이스와 기능들을 활용해 주소록을 넘어 나만의 검색엔진을 구축해보길 바란다.
마치며
엘라스틱서치를 통해 다양한 가능성을 가지고 검색에 입문했다. 검색을 지원하는 다양한 솔루션들이 존재하지만 엘라스틱서치는 검색을 통해 추구해야 할 본연의 목적에 충실 할 수 있도록 쉽고 빠르게 적용할 수 있는 환경을 제공한다.
본문에서는 다루지 않았지만, 추가로 형태소 분석기에 대한 인식과 이해도를 높이길 추천한다. 검색, 특히 전문검색에 대해 전문적인 지식을 쌓기 원하신다면 형태소 분석기는 아주 좋은 무기가 되어줄 것이다.
짧은 글을 통해 엘라스틱의 다양한 기능들과 상세한 내용을 담을 수 없기에 엘라스틱서치의 공식 홈페이지(www.elastic.co)를 통해 보다 상세한 설명과 강의들을 접해보길 권한다. 검색엔진을 구축하기 위해 꼭 엘라스틱서치를 사용해야 하는 더 많은 이유를 확인 할 수 있다.
