엘라스틱서치로 검색엔진 전환하기
지난 글을 통해서 엘라스틱서치를 이용해 검색을 쉽고 빠르게 통해 입문 하게 되었다.
이번 글을 통해서 기존에 검색엔진을 구축하고 운영하는 독자들을 위해 손쉽고 부담없이 엘라스틱서치로 전환할 수 있는 포인트를 제시해보려 한다.
엘라스틱서치는 쉽고 빠르지만, 기존에 RDB나 다른 NoSQL제품을 기반으로 검색엔진을 구축하고 있다면 많은 양의 데이터를 이전하고 기존에 제공하던 검색 기능을 그대로 동일하게 제공하기 쉽지 않다.
기존의 검색엔진에서 사용하던 데이터를 이전하는 것은 bulk API를 통해서 손쉽게 다룰 수 있다. 하지만, 검색 기능을 그대로 이전하는것은 질의 구조나 지원하는 질의 기능을 제대로 파악하지 않으면 원하는 결과를 얻기 힘들다.
엘라스틱서치는 Query DSL이라는 전용 질의 언어를 제공한다. 이를 사용해 기존에 사용하던 검색 기능을 확보하고, 나아가 더 나은 성능과 기능으로서 제시 될 수 있는 부분을 확인 해보도록 하자.
Hellelo, Query DSL!
Query DSL의 Context는 Query와 Filter로 나누거나 혼합하여 구성할 수 있다. Query는 검색하고자 하는 키워드와의 일치성이나 유사성을 스코어로 투영시키기 위한 수단으로 사용된다. 반면, Filter의 경우 특정 영역을 검색하고자 하거나, 검색 키워드의 대상 영역을 한정시키는 역할을 한다.
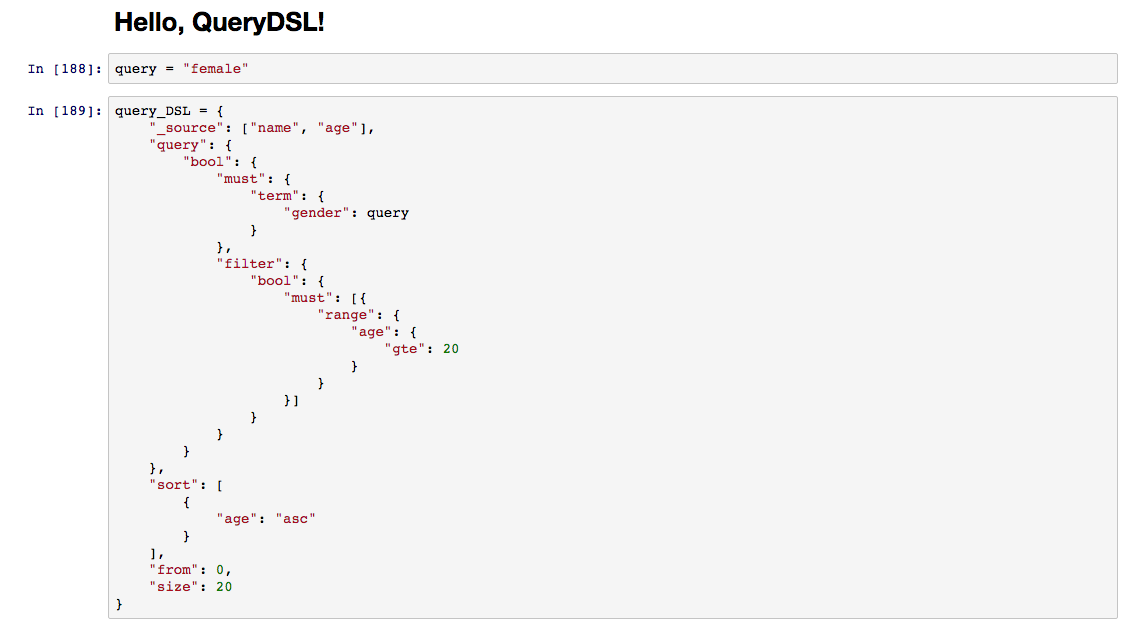
Query와 Filter의 사용은 각 영역별로 서로 다른 질의를 사용하지 않고 공통의 질의들을 할 수 있다. 엘라스틱서치는 이러한 공통의 질의에 대해 다양한 형태로 지원하고 있으며 질의들의 종류로는 Fulltext, Term, Compound, Joining, Geo, Specialized, Span등이 있다. 본 글을 통해서 주로 사용되는 Term, Fulltext, Compound에 관련된 질의에 대해서 짚어보고, 데이터는 “검색” 입문에서 사용한 주소록 예제로 이어가도록 하겠다.
찾고 싶은것을 좁혀 보자: Term level queries
Term 질의들은 명확한 범위나 전제등의 조건을 투영시키기 용의 하기 때문에 앞서 언급한 Filter context를 확보하는데에 주로 사용된다. term 질의들은 매우 다양한 방식을 제공하고 있지만 우리는 그 중에서도 term, terms, range, prefix, wildcard, type 질의를 사용해보도록 하자.
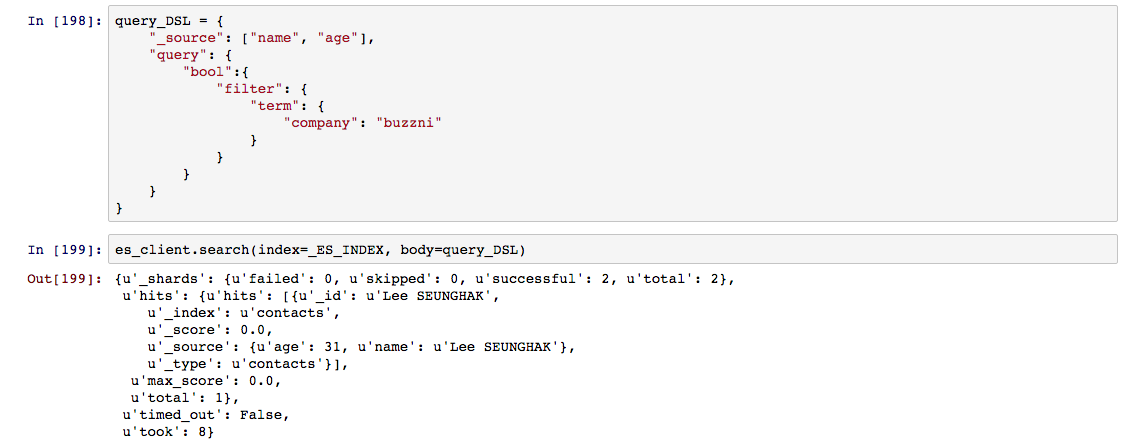
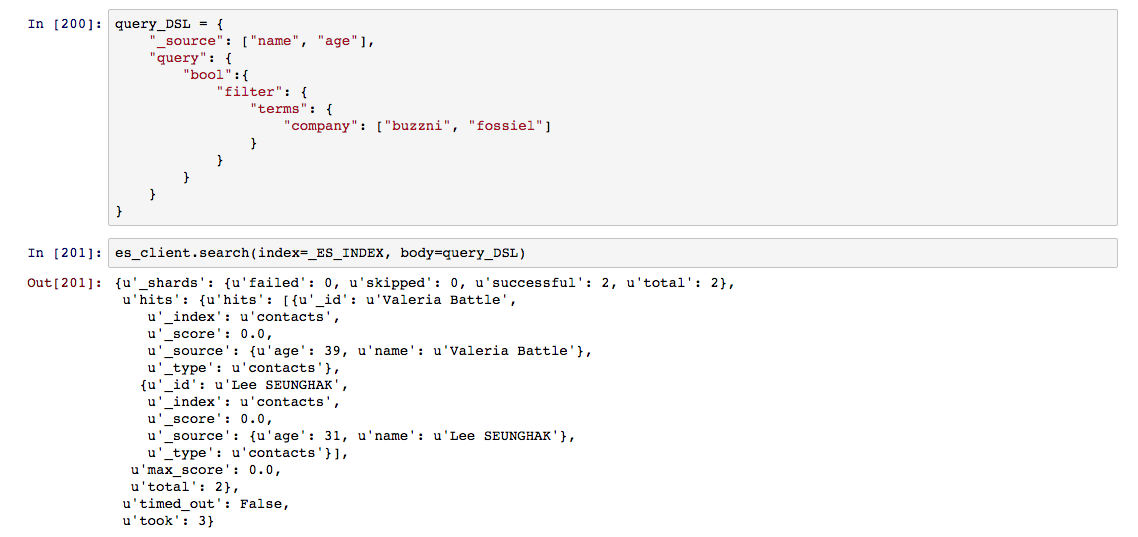
term 질의는 형태소 분석기에 따라 분리된 토큰 단위를 기준으로 완벽히 일치하는 내용을 검색 결과로 제공한다. term과 terms은 단일영역이거나 다중영역을 투영 시키는 정도의 차이를 갖고 있다. terms를 사용시에는 배열 형식으로 값을 전달해야 해주면 된다.

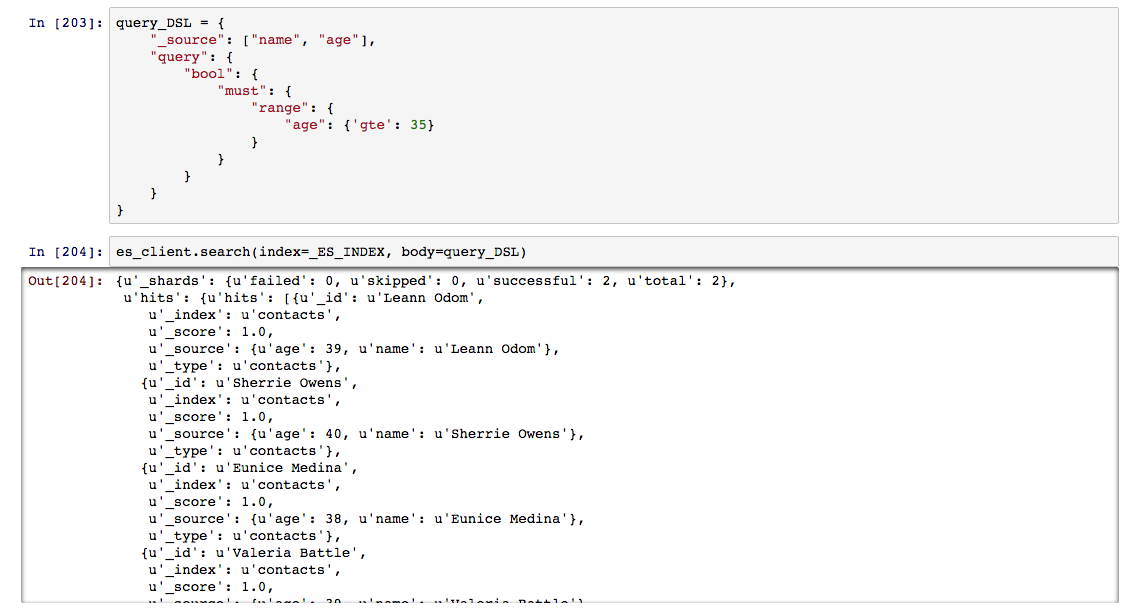
range는 수치 기반의 값의 범위에 해당하는 결과를 제공한다. 범위를 표현하는 방식은 4가지로 지원되며, gte(Greater-than or equal to) , gt(Greater-than), lte(Less-than or equal to), lt(Less-than) 의 부등호 처리 방식을 택하고 있다. 날짜나 시간의 범위를 제한하거나 단순하게 나이제한 같은 부분을 처리 할때 유용하게 사용된다.
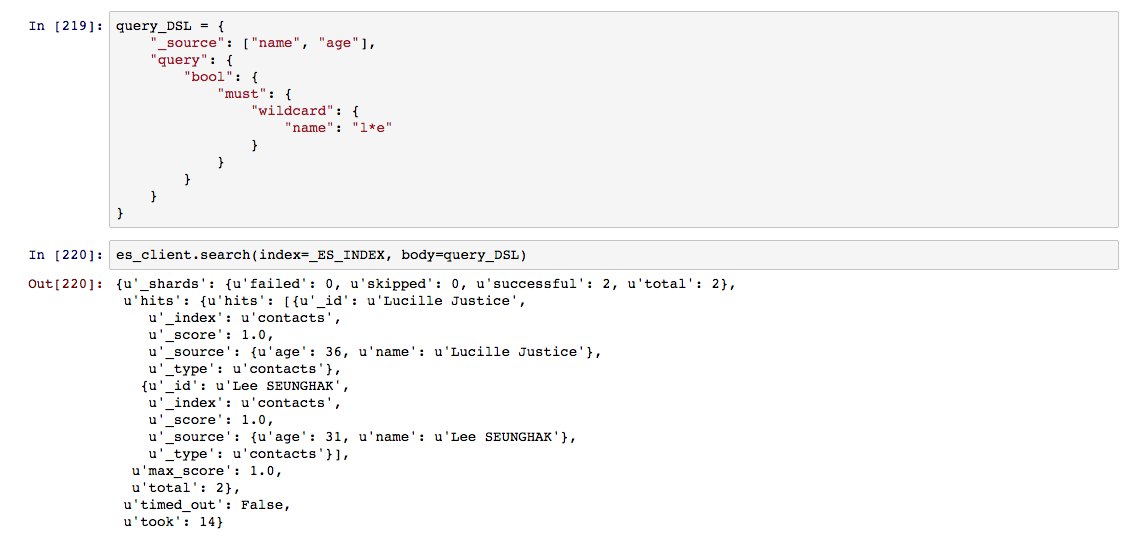
형태소 분석을 사용하지 않는 term 질의 기반에서 접두어나 임의 문자를 사용해야 하는 경우, prefix 와 wildcard 질의를 사용하면 된다. 일부 유효한 예상 검색 결과에 대한 사전정보를 갖고 있는 경우가 이에 해당한다. 한 글자 또는 다수의 글자로 시작되거나 사이 글자로 접근하는 경우에 활용이 가능하다. wildcard는 ‘*’, ‘?’ 사용에 따라 글자 수를 조정이 가능하다.
찾고 싶은 것을 순서대로: Full text queries
Term 질의들로 검색의 범위를 설정 했다면, 형태소 분석기를 기반으로 동작하는 Full text 질의를 사용하여 순위를 부여한 검색 결과를 만들어 보자. 검색 대상 문서와 검색 키워드간의 유사성 분석을 통해 점수로 나타내고 원하는 결과에 근접한 순서로 제공할 수 있도록 도와준다.
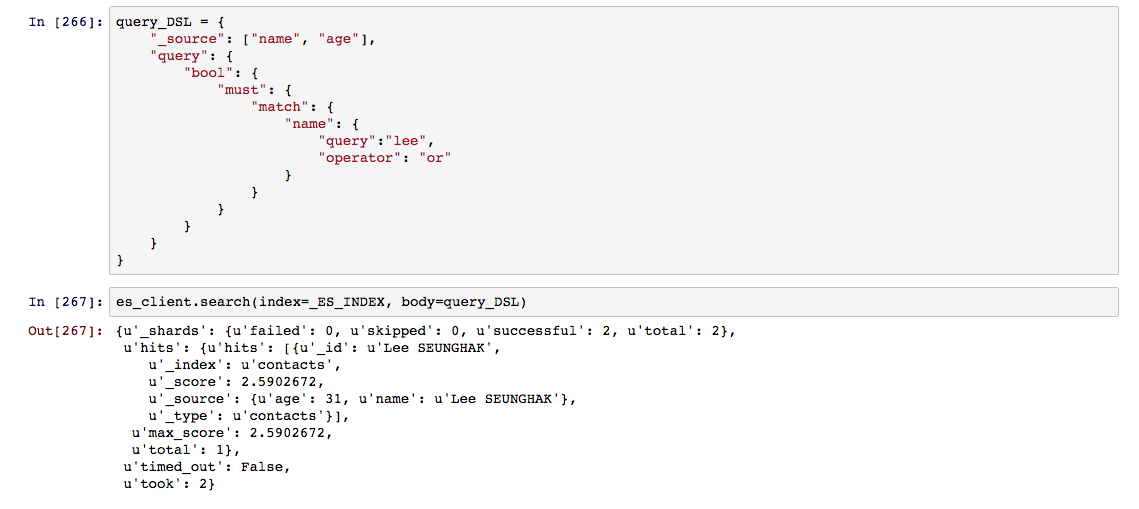
match 질의는 형태소 분석을 거친 검색 대상 문서와 검색 키워드간에 일치하는 부분이 있는 경우 검색결과로 제공한다. operator를 통해 and나 or 로직의 일치 방식을 선택하거나, 형태소 분석기를 지정할 수 있도록 analyzer 옵션을 사용할 수 있다. 또한, 불필요한 롱테일 성격의 검색 결과를 예방할 수 있도록 minimum_should_match를 통해 최소 일치 범위를 설정이 가능하다.
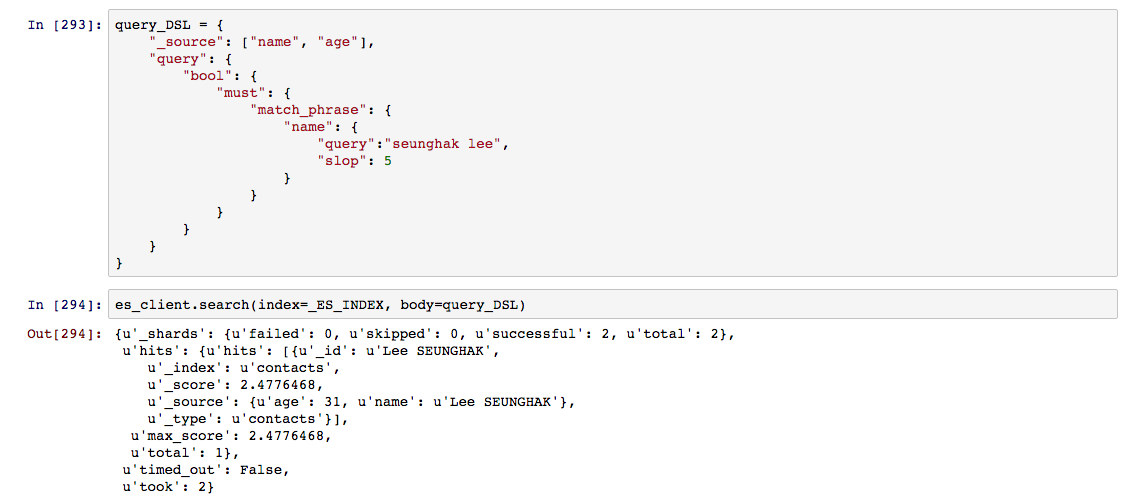
일부 영역에 대해 일치하는 검색결과가 아닌 구문 전체가 일치해야 검색이 가능하도록 하기 위해서는 match_phrase 질의를 사용하면 된다. 단, 모든 검색 키워드에 대해 띄어쓰기를 포함하여 정확한 위치로 요청해야 검색 결과로 도출되는 까다로운 질의이다. 하지만, 동일한 단어 구성이지만 단어의 위치가 도치된 형태에 대해서는 slop 옵션을 통해 완전 일치의 허용 정도를 조절 할 수 있다.
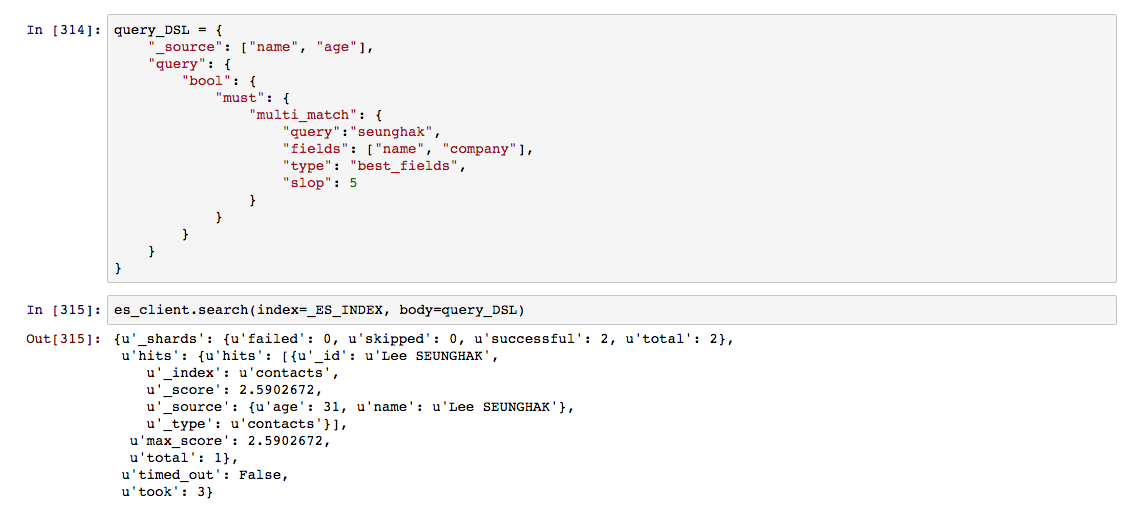
match 질의는 단일 필드만을 대상으로 검색을 지원하기 때문에, 다중 필드를 검색 대상으로 사용하려면 multi_match 활용 해야 한다. multi_match는 기본적으로 best_fields, most_fields, cross_fields, phrase, phrase_prefix 타입을 지원한다. 다중 필드를 대상으로 하기 때문에 검색 정책에 따라 필요한 타입을 선택해야 한다.
최선을 위한 조합: Compound queries
Compound 질의들은 검색을 위한 다양한 질의를 모으고 모아서 공통 목적을 가진 질의 형태로 만들고자 함을 지원해준다. Constant Score, Bool, Dis Max, Function Score, Boosting등이 이에 해당되며 필수 조건은 아니지만 검색 성능을 끌어올리는데에 필수적이라고 할 수 있다. 그 중에 가장 보편적이고 많이 쓰이는 Bool 질의에 대해서 사용해보도록 하자.
Bool 질의는 must, filter, should, must_not으로 구성되며, filter의 경우 앞서 사용했던 Filter Context의 역할을 해주는 영역이라고 할 수 있다. 각 영역은 이름에서 주는 의미 그대로 직관적으로 인지하면 된다. must는 영역내에서 해당되는 조건들을 모두 만족해야 함을, must_not는 must와 반대로 절대로 사용하지 않을 조건을, should는 부분 조건에 만족하는 경우를 정의 한다.
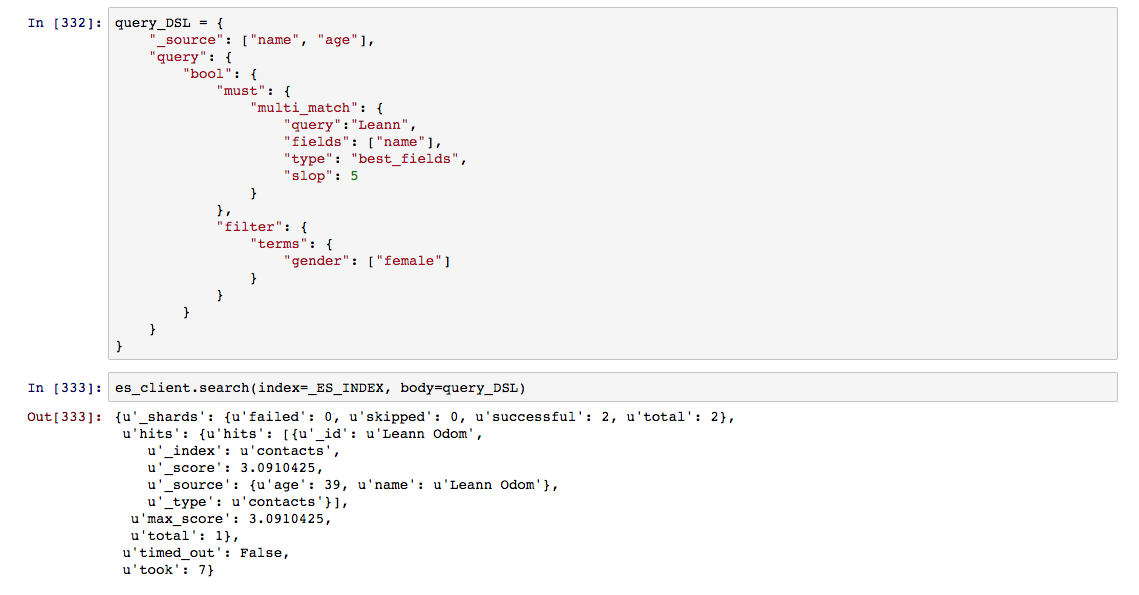
필터 조건은 특정한 영역에 한정하는 경우를 제외 하고는 느슨하게 처리 할 수 밖에 없기 때문에 형태소 분석이 전제가 되는 질의를 적절히 사용해야 한다. 특히, 검색결과에 점수를 나열하여 유사성이 높은 순서로 검색결과가 투영되어야 하는 경우 필터만으로 검색결과에 포함되어 목적성을 흐리기 쉽다.
마치며
query DSL은 엘라스틱서치의 “꽃” 이라 할 수 있다. 찾고자 하는 것을 잘 찾아주는것이 검색의 궁극적인 목적인데 이 잘 찾아 준다라는 표현이 가능하도록 해주는것이 바로 엘라스틱서치가 query DSL에게 부여한 역할 이다.
query DSL은 엘라스틱서치 검색기능의 모든것을 담고 있다. 때문에 query DSL에 대해 잘 알고 있는 것이 새로운 검색엔진을 만드는데도 중요하지만, 기존에 구축된 검색엔진을 엘라스틱서치로 전환하기 위해 준비해야 할 가장 중요한 내용이다.
기존에 다른 검색 엔진에서 주로 사용하던 기능이나 부족했던 기능에 대해 query DSL을 통해 직접 구현 해보기를 권한다. 엘라스틱 서치는 시스템 측면의 엔진 구축에 소요되는 리소스가 비교적 매우 작기 때문에 검색 기능의 본연에 더 많은 시간을 할애 할 수 있을 것이고, 궁극적으로 검색 성능 자체에 변화를 가져다 줄 것이다.
